
Googleの検索オプション
数年前だったか、少し話題になったこともある内容ですがGoogle検索には様々な検索オプションがります。
画面上でかけられるフィルタ
【すべてのフィルタ】
画像、地図、ショッピング、動画、ニュース、書籍、フライト、ファイナンス
【ツール】
言語、期間指定、すべての結果or完全一致
上記が誰でもすぐに使える検索オプションですが、これ以外にコマンドで使える物があります。
Google検索コマンド(検索演算子)一覧
一般的なGoogle検索コマンド(検索演算子)の一覧です。これらの演算子を使用することで、より具体的な検索結果を得ることができます。
- site:特定のウェブサイト内を検索する(例:site:example.com)
- filetype:特定のファイルタイプを検索する(例:filetype:pdf)
- related:関連するウェブサイトを検索する(例:related:example.com)
- intitle:タイトルに特定のキーワードを含むページを検索する(例:intitle:keyword)
- allintitle:タイトルにすべての指定キーワードを含むページを検索する(例:allintitle:keyword1 keyword2)
- inurl:URLに特定のキーワードを含むページを検索する(例:inurl:keyword)
- allinurl:URLにすべての指定キーワードを含むページを検索する(例:allinurl:keyword1 keyword2)
- intext:本文に特定のキーワードを含むページを検索する(例:intext:keyword)
- allintext:本文にすべての指定キーワードを含むページを検索する(例:allintext:keyword1 keyword2)
- AROUND:指定したキーワードが別のキーワードの周囲に出現するページを検索する(例:keyword1 AROUND(2) keyword2)
- link:特定のURLへのリンクを持つページを検索する(例:link:example.com)
- cache:Googleのキャッシュに保存された特定のページを表示する(例:cache:example.com)
- define:特定の単語やフレーズの定義を表示する(例:define:word)
- stocks:特定の株式の情報を表示する(例:stocks:goog)
- weather:特定の場所の天気予報を表示する(例:weather:location)
Google検索についてもっと学びたいという方は以下のGoogle検索セントラルをご覧になってみてください。

サーバーから極秘ファイルぶっこ抜く
さて、前置きが長くなりましたが今回の本題「WEBサイトから秘密のファイルをブチ抜く方法」についてみていきましょう。その前に、一つ注意書きです。これは悪用するためではなくあくまでセキュリティ対策として、こういう方法があるので気を付けましょうという注意喚起です。
前置きで書いた「検索演算子」を用いて特定のサイトから非公開文書を引っこ抜く方法ですが、「filetype:」という演算子を使います。日本の多くの企業は「PDF」というタイプのファイルで書類や文書をやり取りしてることが多いです。そしてこれらのPDFは社内で管理されていますが、各社自分たちで使っているサーバーに入れて管理していたりします。
そこで「filetype:PDF」という演算子を使って「filetype:PDF 社外秘」と検索してみます。

黒塗りばっかりで申し訳ないですが、さすがに出せないのでご勘弁ください。
このように本来流出してはいけない文書がずらっと出てきます。
と、ここまでは数年前にも話題になったことがある内容です。
この話には続きがあって、検索演算子は一つだけしか使えないわけではありません。
複数の検索演算子を同時に使うことができます。
そこで「site:」という検索演算子も一緒に使います。
filetype:pdf site:https://www.mhlw.go.jp/
サイトURLを指定してPDFに絞って検索するという命令です。
今回はサンプルで厚生労働省のHPから取りました。
※恐らくちゃんと公式に出している文章だと思うので問題ないと思います
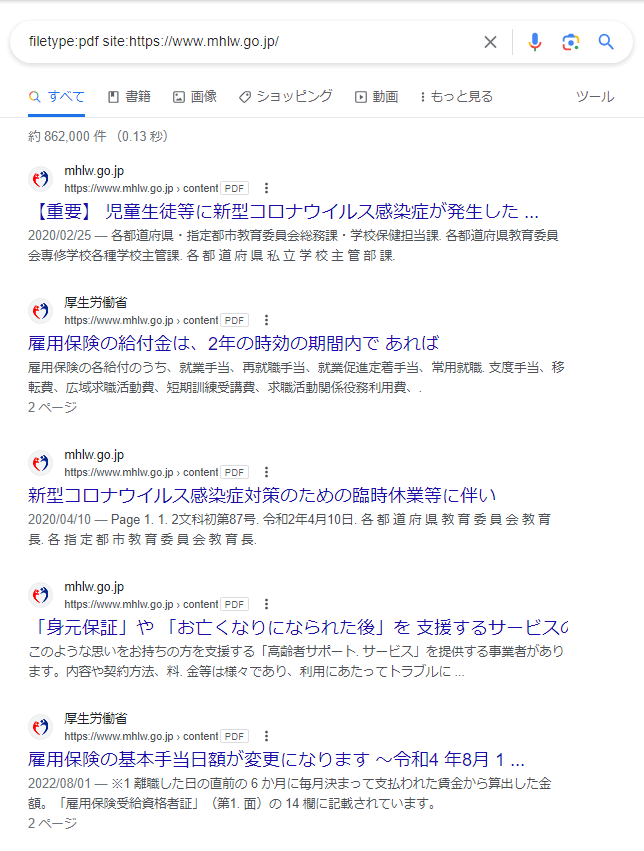
このように、サイトのURLを指定すると特定のサイトでアップされているPDFに的を絞って検索できるわけです。ほとんどの場合、どこかの記事を経由してダウンロードできるような物ばかりですが、たまに絶対に流出させてはいけないファイルだろって言うのがあったりします。
案外あっさり情報は洩れます
これが仮に大企業などが持っている顧客情報のような重大なデータだったら、あっという間に社会問題になってしまいます。
社内ポータルなんかでファイルのやり取りをする場合なども、外部に繋がってるサーバーだった場合、わざわざハッキングなんてしなくても流出する危険性があります。
そして使っているサイトに関しても注意点があります。例えばホームページを入れているサーバーとデータを保管しているサーバーが同一の共用サーバーだった場合、一つのドメインから同じサーバーを利用している他のドメインを割り出すことができます。
そこに以下のようなドメインがあったとします。
sample.com
date.sample.com
というように、サブドメインでデータサーバーだなとわかるような作りになっていたら余計にわかりやすいです。そして割り出したドメインを基に、「site:」検索演算子を使い的を絞ると検索からデータサーバーも見れてしまうという現象が起きます。
セキュリティ対策はしっかりやろう
悪意のあるハッカーだったら同一サーバーにわかりやすくデータサーバーなんておいてたら取ってくれと言ってるような物なので検索演算じゃない方法でハックしてしまう可能性だって考えられるのでこういうのも一緒に気を付けたいポイントです。
きちんとしたセキュリティ対策をしているところなら、こんな方法で漏れるなんてことはないですが、セキュリティ対策をちゃんとやってない場合は案外あっさり社外秘の文章が漏れてしまうなんてことが起こりえます。十分注意してください。


コメント